ORGANISASI BERKAS INDEKS SEKUENSIAL ==================================
• PENGERTIAN BERKAS INDEKS SEKUENSIAL
Salah satu cara yang paling efektif untuk mengorganisasi kumpulan record-record yang membutuhkan akses record secara sekuensial maupun akses record secara individu berdasarkan nilai key adalah organisasi berkas indeks sekuensial.
Jadi berkas indeks sekuensial merupakan kombinasi dari berkas sekuensial dan berkas relatif.
Adapun jenis akses yang diperbolehkan, yaitu :
• Akses Sequential
• Akses Direct
Sedangkan jenis prosesnya adalah :
• Batch
• Interactive
Struktur berkas Index Sequential
• Index --> Binary Search Tree
• Data --> Sequential
Indeksnya digunakan untuk melayani sebuah permintaan untuk mengakses sebuah record tertentu, sedangkan berkas data sequential digunakan untuk mendukung akses sequential terhadap seluruh kumpulan record-record. ------------------------------------------
• STRUKTUR POHON
Sebuah pohon (tree) adalah struktur dari sekumpulan elemen, dengan salah satu elemennya merupakan akarnya atau root, dan sisanya yang lain merupakan bagian-bagian pohon yang terorganisasi dalam susunan berhirarki, dengan root sebagai puncaknya.
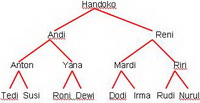
Contoh umum dimana struktur pohon sering ditemukan adalah pada penyusunan silsilah keluarga, hirarki suatu organisasi, daftar isi suatu buku dan lain sebagainya.
Contoh :
Gambar 1. Silsilah Keluarga Akar pohon (root) adalah Handoko
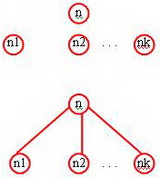
Secara rekursif suatu struktur pohon dapat didefinisikan sebagai berikut :
• Sebuah simpul tunggal adalah sebuah pohon.
• Bila terdapat simpul n, dan beberapa sub-pohon T1,T2,...,Tk, yang tidak saling berhubungan, yang masing-masing akarnya adalah n1,n2,...,nk , dari simpul/sub pohon ini dapat dibuat sebuah pohon baru dengan n sebagai akar dari simpul-simpul n1,n2,...,nk.
Gambar 2. Definisi struktur pohon ------------------------------------------
• POHON BINER
Salah satu tipe pohon yang paling banyak dipelajari adalah pohon biner.
Pohon Biner adalah pohon yang setiap simpulnya memiliki paling banyak dua buah cabang/anak.
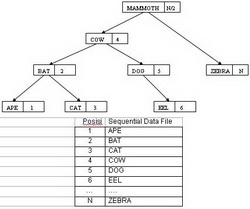
Gambar 3. Beberapa contoh Pohon Biner
Pada gambar tersebut memperlihatkan struktur berkas indeks sekuensial dengan sebuah indeks berikut pointer yang menuju ke berkas data sekuensial. Pada contoh gambar tersebut, indeksnya disusun berdasarkan binary search tree. Indeksnya digunakan untuk melayani sebuah permintaan untuk mengakses sebuah record tertentu, sedangkan berkas data sekeunsial digunakan untuk mendukung akses sekuensial terhadap seluruh kumpulan record-record. ------------------------------------------
• IMPLEMENTASI ORGANISASI BERKAS INDEKS SEKUENSIAL
Ada 2 pendekatan dasar untuk mengimplementasikan konsep dari organisasi berkas indeks sekuensial
• Blok Indeks dan Data (Dinamik)
• Prime dan Overflow Data Area (Statik)
Kedua pendekatan tersebut mengunakan sebuah bagian indeks dan sebuah bagian data, dimana masing-masing menempati berkas yang terpisah.
Alasannya :
Karena mereka diimplementasikan pada organisasi internal yang berbeda. Masing-masing berkas tersebut harus menempati pada alat penyimpan yang bersifat Direct Access Storage Device (DASD). ------------------------------------------
• BLOK INDEKS DAN DATA
Pada pendekatan ini berkas indeks dan berkas data diorganisasikan dalam blok. Berkas indeks mempunyai struktur tree, sedangkan berkas data mempunyai struktur sekuensial dengan ruang bebas yang didistribusikan antar populasi record.
Pada gambar tersebut ada N blok data dan 3 tingkat dari indeks. Setiap entry pada indeks mempunyai bentuk (nilai key terendah, pointer), dimana pointer menunjuk pada blok yang lain, dengan nilai key-nya sebagai nilai key terendah. Setiap tingkat dari blok indeks menunjuk seluruh blok, kecuali blok indeks pada tingkat terendah yang menunjuk ke blok data.
Jika sebuah permintaan untuk mengakses record tertentu, misal kita ingin mengakses dengan nilai key BAT, indeks dengan tingkat tertinggi (dalam hal ini blok indeks 3-1) yang pertama yang akan dicari pada contoh ini, pointer dari AARDVARK menunjuk blok indeks 2-1. Pointer yang ditunjuk pada kotak tersebut adalah pointer yang berisikan AARDVARK, yang akan menunjuk ke blok indeks 1-1. Pointer berikutnya yang akan ditunjuk adalah pointer yang berisi BABOON, yang selanjutnya akan menunjuk blok data 2. Blok data ini akan mencari untuk record dengan key tujuan, yaitu BAT, dimana pada blok ini record tersebut ditemukan.
Permintaan untuk akses data dalam urutan sekuensial dilayani dengan mengakses blok data dalam urutan sekuensial. Sebagai catatan blok data merupakan consecutive secara logik dan bukan consecutive secara fisik. Dalam hal ini, blok data harus dihubungkan secara bersama dalam urutan secara logik, seperti terlihat pada gambar di halaman 5.
Misal :
Setiap blok data mempunyai ruang yang cukup untuk menampung 5 record dan setiap blok indeks mempunyai ruang yang cukup untuk menyimpan 4 pasang (nilai key, pointer).
Parameter ini biasanya sudah dilengkapi dengan rutin dukungan sistem manajemen data, pada saat berkas binatang ini dibentuk.Jika kita menginginkan penyisipan maupun penghapusan terhadap isi berkas, maka blok indeks dan blok data akan dibuat dengan sejumlah ruang bebas, yang biasanya disebut sebagai padding dan pada gambar ditunjukkan sebagai irisan.
Permintaan :
INSERT APE
INSERT AIREDALE
Hanya blok data 1 yang digunakan dan hasilnya ditunjukkan pada gambar dibawah ini :
Entry pada blok harus diletakan berdasarkan urutan sekuensial ascending.
Permintaan :
INSERT ARMADILLO
Pencarian dari struktur indeks menyatakan bahwa ARMADILLO seharus-nya menempati blok data 1, tetapi blok tersebut sudah penuh.
Untuk mengatasi keadaan tersebut, blok data 1 dipecah dengan memodifikasi blok indeks 1-1.
Separuh dari isi blok data, tetap menempati blok tersebut dan separuhnya lagi dipindahkan ke blok yang baru dibuat, yaitu blok data 1A.
Hasilnya ditunjukkan pada gambar dibawah ini
Permintaan :
INSERT CAT
INSERT BEAR
INSERT BOBCAT
Akan mengisi blok data 2, tetapi blok data tersebut harus dipecah menjadi blok data 2 dan 2A.
Blok indeks 1-1 sudah penuh dan tidak dapat memuat pointer pada blok data 2A, sehingga inipun harus dipecah, dengan cara mengubah penafsiran indeks tingkat 2.
Jika blok indeks pada tingkat paling tinggi (dalam hal ini indeks tingkat 3) sudah penuh, maka harus dipecah, sehingga sebuah indeks tingkat yang baru akan ditambahkan pada indeks tree.
Maka seluruh pencarian langsung, memerlukan pengaksesan empat blok indeks dan sebuah blok data.
------------------------------------------
• PRIME DAN OVERFLOW DATA AREA
Pendekatan lain untuk mengimplementasikan berkas indek sekuensial adalah berdasarkan struktur indek dimana struktur indek ini lebih ditekankan pada karakteristik fisik dari penyimpanan, dibandingkan dengan distribusi secara logik dari nilai key.
Indeksnya ada beberapa tingkat, misalnya tingkat cylinder index dan tingkat track index. Berkas datanya secara umum diimplementasikan sebagai 2 berkas, yaitu prime area dan overflow area.
Misal setiap cylinder dari alat penyimpanan mempunyai 4 track.
Pada berkas binatang ada 6 cylinder yang dialokasikan pada prime data area.
Track pertama (nomor 0) dari setiap cylinder berisi sebuah indeks pada record key dalam cylinder tersebut.
Entry pada indeks ini adalah dalam bentuk :
nilai key terendah, nomor track
Dalam sebuah track data, tracknya disimpan secara urut berdasarkan nilai key.
Tingkat pertama dari indeks dalam berkas indeks dinamakan master index.
Entry pada indeks ini adalah dalam bentuk :
nilai key tertinggi, pointer
Tingkat kedua dari indeks dinamakan cylinder index.
Indeks ini berisi pointer pada berkas prime data dan entry-nya dalam bentuk :
nilai key tertinggi, nomor cylinder
Jika sebuah permintaan untuk mengakses record tertentu, misal kita akan mengakses dengan nilai key BAT, pertama akan dicari pada master index. Karena BAT ada didepan LYNX, maka pointer dari LYNX akan menunjuk ke cylinder index. Karena BAT ada didepan ELEPHANT, maka pointer dari ELEPHANT akan menunjuk ke track 0 dari cylinder 1. Karena BAT ada dibelakang BABOON dan didepan COW, maka pointer dari BABOON akan menunjuk ke track 2, yang mencari secara sekuensial, sampai BAT ditemukan.
Permintaan untuk mengakses data secara sekuensial akan dilayani dengan mengakses cylinder dan track dari berkas data prime secara urut.
Misal setiap track dari berkas prime data mempunyai ruang yang cukup untuk menampung 5 record ( jika penyisipan dan penghapusan terhadap berkas dilakukan, maka akan dibentuk padding).
Permintaan :
INSERT APE
INSERT AIREDALE
Akan mudah dilayani. Hanya track data 1 dari cylinder 1 yang akan digunakan dan hasilnya ditunjukkan pada gambar dibawah ini :
Permintaan :
INSERT ARMADILLO
Agak sulit ditangani. Pencarian struktur indeks menyatakan bahwa ARMADILLO seharusnya menempati track 1 dari cylinder 1, tetapi track tersebut sudah penuh.
Untuk mengatasi keadaan tersebut diperlukan overflow data area.
Overflow data area ini merupakan berkas yang terpisah dari prime data area, tetapi overflow area ini ditunjukan oleh entry prime data area.
Hasilnya ditunjukkan pada gambar dibawah ini
Karena ARMADILLO seharusnya berada setelah kelima entry pada track 1 dari cylinder 1, tetapi karena track ini sudah penuh, maka ARMADILLO dipindahkan ke overflow data area. Indeks track dari cylinder 1 harus dimodifikasi untuk memperlihatkan bahwa ada sebuah record pada overflow area yang secara logik seharusnya menempati pada akhir dari track 1, sehingga penambahan dari entry itu adalah :
<ARMADILLO,ovfl-ptr>
Dengan ovfl-ptr adalah :
<cylinder, track, record>
Permintaan :
INSERT CAT
INSERT BEAR
INSERT BOBCAT
Akan mengisi track 2 dari cylinder 1 pada prime data area, tetapi pengisian tersebut mengakibatkan penggunaan overflow area. Perhatikan CAT dipindahkan ke overflow area, karena entry pada prime track tidak hanya harus dalam urutan, tetapi juga entry tersebut harus mendahului suatu entry overflow dari track tersebut.
Gambar penyimpanan berkas index sequential ------------------------------------------ File Random
+ Perintah untuk pemasukan data file random :
- OPEN “R”, ............... 1
- FIELD # .................... 2
- PUT # ....................... 3
- CLOSE # .................. 4
Add 1 : Open file sebagai random file (“R”)
ln OPEN “R”, #nomor buffer, “nama file”,l
ln : nomor baris program
l : menyatakan jumlah karakter untuk satu record, jika tidak
diisi dianggap 128 byte
100 OPEN “R”,#1,”B:DTMHA.DAT”,64
Add 2 : Field #, mendefinisikan panjang masing-masing field
ln FIELD #(nomor buffer), l1 AS var1, l2 AS var2, ..........
ln : nomor baris
l1 : panjang variabel
var1 : nama variabel
200 FIELD #1, 8 AS NPM$, 25 AS NAMA1$
Add 3 : PUT #, menyimpan record
ln PUT #(nomor buffer), record ke
300 PUT #1, 130
Add 4: Close #, menutup file yang telah dibuka
ln CLOSE #(nomor buffer)
1000 CLOSE #1
Untuk merekam data maka penulisannya dalam record harus didefinisikan dahulu letaknya. Dikenal 2 jenis hukum yaitu hukum kiri atau hukum kanan.
- LSET : dipakai apabila penulisan field pada daerah yang telah ditentukan panjangnya harus menepi kiri
- RSET : dipakai apabila penulisan field pada daerah yang telah ditentukan panjangnya menepi kanan
Perbedaan antara penyimpanan data secara sequential dengan secara random yaitu : dalam file sequential dapat menyimpan data secara numerik sedangkan dalam file random penyimpanan data tidak bisa.
Penyimpanan data dalam file random harus berbentuk string.
Perintah yang digunakan untuk merubah numerik menjadi string dengan menggunakan :
• MKI$ : Untuk integer
• MKS$ : Untuk single precision
• MKD$ : Untuk double precision
Sedangkan perintah yang digunakan untuk pemanggilan kembali atau merubah dari string menjadi numerik adalah
• CVI : untuk integer
• CVS : untuk single precision
• CVD : untuk double precision
+ Perintah untuk pemanggilan secara random
- OPEN “R”
- FIELD #
- GET #
- CLOSE # ------------------------------------------ Organisasi Berkas dengan Banyak Key
Organisasi berkas yang memperbolehkan record diakses oleh lebih dari satu key field.
Teknik yang dipakai untuk organisasi ini, hampir semua pendekatan bergantung pada pembentukan indeks yang memberi akses langsung dengan nilai key.
Teknik untuk pemberian hubungan antara sebuah indek dan data record dari berkas secara :
- Inversion
- Multi List
Pengulangan data dari beberapa file bukan merupakan cara yang baik untuk mengakses record dengan berbagai cara, cara ini memerlukan space yang besar distorage dan kesulitan pada waktu peng-update-an record secara serantak. Untuk mengatasi masalah diatas maka digunakan organisasi berkas banyak key yang umumnya di-implementasikan dengan pembentukan banyak index untuk memberikan akses yang berbeda terhadap record data. ------------------------------------------ Organisasi Inverter File
Suatu pendekatan dasar untuk memberikan hubungan antara sebuah indek dan data record dari file (inversi).
Sebuah key pada index inversi mempunyai semua nilai key dimana masing-masing nilai key mempunyai penunjuk ke record yang bersangkutan. (inverted file)
Sebuah index inversi dapat dibuat bersama sebuah relatif file atau sebuah index sequential.
Primary key : key yang dipakai untuk menentukan struktur storage dari file
Secondary Key : key yang lainnya
File yang mempunyai index inversi untuk setiap data field disebut COMPLETELY INVERTED, file yang bukan completely inverted tapi paling sedikit mempunyai satu index inversi disebut PARTIALY INVERTED FILE.
Sebuah variasi dari struktur index inversi adalah pemakaian secondary key dan primary key dari inderect addressing. Pendekatan ini membiarkan file yang direorganisasi dan restructuring secara fisik tanpa menyebabkan indek file. ------------------------------------------ Organisasi Multi List File
Suatu pendekatan lain yang memberikan hubungan antara sebuah index dan data record dari sebuah file disebut Organisasi multi list file.
Seperti sebuah inverted file , sebuah multi list file mempunyai sebuah index untuk setiap secondary key. Organisasi multi list file berbeda dengan inverted file, dimana dalam index inversi untuk sebuah nilai key mempunyai sebuah penunjuk untuk sebuah data record dengan nilai key, sedangkan dalam index multi list untuk sebuah nilai key mempunyai hanya sebuah penunjuk untuk data record pertama dengan nilai key. Data record mempunyai sebuah penunjuk untuk data record selanjutnya dengan nilai key dan seterusnya. Maka terdapat sebuah linked list dari data record untuk setiap nilai dari secondary key.